Morphogen2, from its outset, was a project designed to make complex infrastructure developer friendly and accessible. Morphogen2, a continuation of Vidya’s summer internship project, is a Python library that runs in the CI/CD pipelines for projects. The idea is that you simply check in code that describes the infrastructure for your target environment(s) and these environment(s) will be automatically created/updated/managed for you.
It plays well and integrates with the existing Ginkgo ecosystem of tools in all sorts of ways as well. Morphogen2 code can describe one or many microservices, one or many Lambdas, etc. etc.. It can build discrete chunks of infrastructure but it can also build larger, more complex entities. It can also build complicated ecosystems that consist of complex architectures integrated with various discrete chunks of infrastructure like RDS instances, S3 buckets, and ECR repos. The project has a dedicated team on DevOps that I tech lead but anyone in the company is welcome to contribute to it. Sure you can make infrastructure in vanilla Terraform or CloudFormation, but we’ll get into some code examples and I’ll start to show some of the reasons why you would waste a lot of time trying to replicate the stuff you can easily cookie cutter out with Morphogen2.
An example of a more complex architecture you can pretty quickly stand up in Morphogen2 would be this architecture for what’s called “serverless_https_endpoint”:
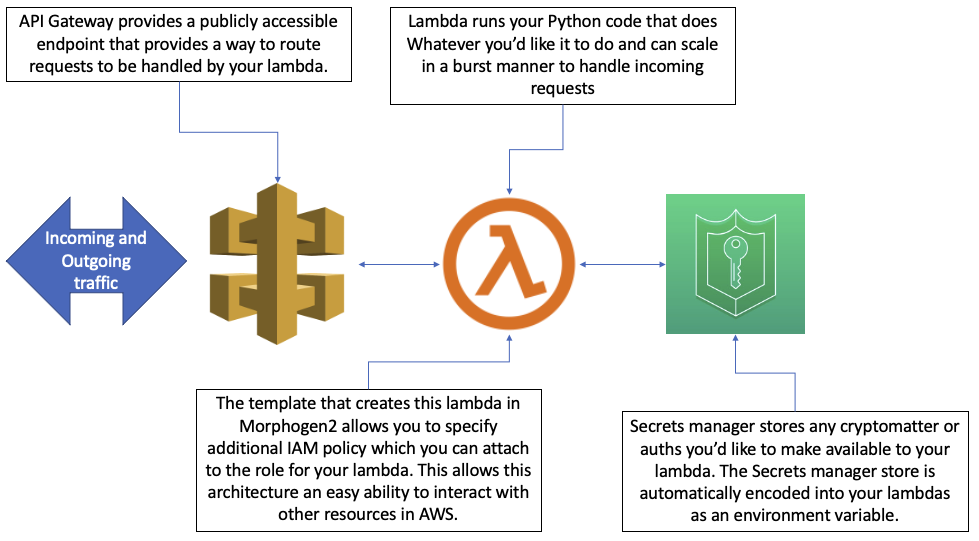
Another example would be the microservices architectures Morphogen2 creates which generally look something like this:
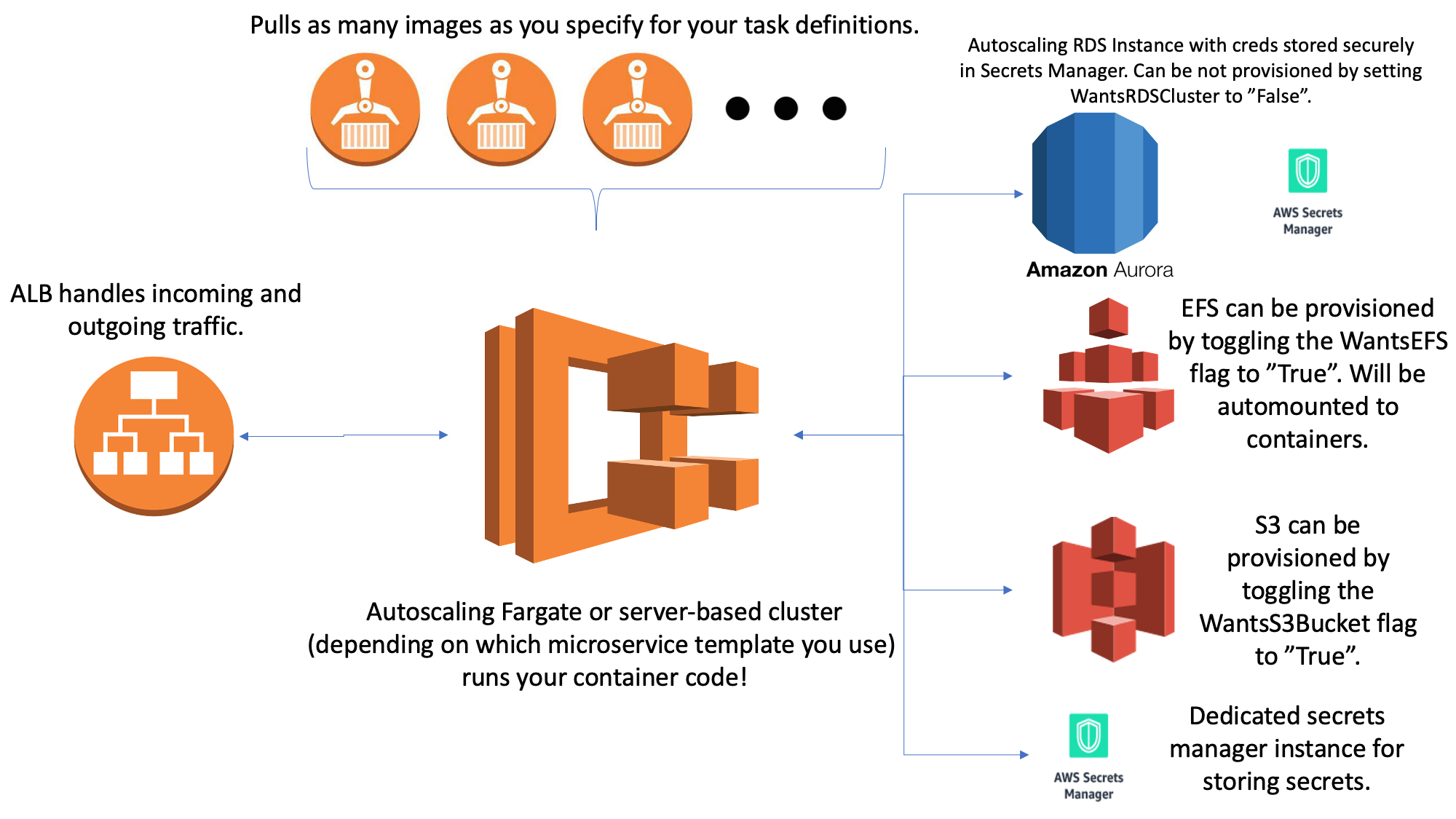
The library also provides a bunch of tools that can do complex actions with Lambdas like really rapidly creating Lambda layers with specific packages or automatically deploying new code when it’s checked into a project with git. You can also do things like write code that scans a bunch of different environments for specific infrastructure and if that infrastructure doesn’t exist it creates it or if it does exist it updates it. And these examples are only just beginning to scratch the surface of the vast collection of tools we’ve accumulated within Morphogen2 from all its different contributors across a whole host of different teams.
A lot of the code to do particularly complex things in AWS with Morphogen2 is very concise compared to other offerings. It incorporates best practices in the infrastructure it builds and provides a whole bunch of tools to auto discover and build on top of existing infrastructure. Want to build an HTTPS endpoint that serves requests and is backended by a Lambda? Here are fewer than 50 lines of Python code that will do that for you:
from morphogen2 import Stack, Garden, Utilities, Probe
import os
if __name__ == "__main__":
# initializing a garden object
a_morphogen2_garden_object = Garden.garden()
# fetching template
a_garden_template_object = a_morphogen2_garden_object.fetch('serverless_https_endpoint')
# building the template (this could easily be json.loads() from a json if you'd prefer it to be!)
Parameters = {"ServiceName": "<name_you_want_your_service_to_have>"}
a_garden_template_object.build(Parameters)
# getting a utilities object
a_utilities_object = Utilities.utilities()
a_utilities_object.create_assume_role_config('<role_to_assume_to_target_account>', '<account_number_you_want_to_deploy_to>', '<region_to_deploy_to>')
# getting a stack object
a_morphogen2_stack_object = Stack.stack()
a_morphogen2_stack_object.create_assume_role_config('<role_to_assume_to_target_account>','<account_number_you_want_to_deploy_to>','<region_to_deploy_to>')
#if the stack doesn't exist already create it, otherwise do an update.
a_morphogen2_stack_object.universal_deploy_update_from_template(a_garden_template_object, '<name_you_want_your_resource_stack_to_have>')
# getting a probe object
a_probe_object = Probe.probe()
a_probe_object.create_assume_role_config('<role_to_assume_to_target_account>', '<account_number_you_want_to_deploy_to>', '<region_to_deploy_to>')
# Wait 5 minutes for stack to build. If the stack doesn't build successfully in that time then error out.
boolean_value = a_probe_object.determine_if_cloudformation_is_done_building('<name_you_want_your_resource_stack_to_have>',300)
if boolean_value:
print('Stack built successfully!')
else:
raise ValueError('Stack did not build successfully within 300 seconds!')
# query completed stack for output values
outputs_dictionary = a_probe_object.fetch_outputs_from_cloudformation_stack('<name_you_want_your_resource_stack_to_have>')
# deploy lambda code
a_utilities_object.update_code_and_attach_layer_to_python_lambda_function(outputs_dictionary['LambdaFunctionARN'],
os.path.join(os.path.dirname(os.path.realpath(__file__)),'code'),
'main.lambda_handler',
os.path.join(os.path.dirname(os.path.realpath(__file__)),'requirements','requirements.txt'))
That’s a sanitized version of a real-life deploy script I built for an app at Ginkgo. I set it up as a Gitlab CI/CD job and every time I check in new Lambda code it goes out and deploys my code for me. It also takes a path to a requirements.txt file and turns that into a Lambda layer and attaches it to my function so that it has all the dependencies it needs to run. I built a whole app around that script in an afternoon and it’s been running reliably to this day months later.
Would you like to set up an autoscaling microservice in ECS on Fargate? Great! Here are fewer than 20 lines of code that do it for you:
from morphogen2 import Stack, Garden, Probe
if __name__ == "__main__":
# initializing objects
a_morphogen2_garden_object = Garden.garden()
a_morphogen2_stack_object = Stack.stack()
a_probe_object = Probe.probe()
#updating template
Parameters = {'LogGroupName':'<whatever_name_you_want_your_logs_to_have>',
'Images':['<account_number_you_want_to_deploy_to>.dkr.ecr.<region_to_deploy_to>.amazonaws.com/ecrreponame:latest'],
'ContainerPorts':[80],
'Certificate':'<arn_of_certificate_you_want_to_use>',
'WantsEFS':'True',
'WantsRDSCluster':'True',
'WantsS3Bucket':'True'}
a_garden_template_object_for_serverless_autoscaling_microservice = a_morphogen2_garden_object.fetch('serverless_autoscaling_microservice')
a_probe_object.create_assume_role_config('<role_to_assume_to_target_account>', '<account_number_you_want_to_deploy_to>', '<region_to_deploy_to>')
a_garden_template_object_for_serverless_autoscaling_microservice.build(Parameters,probe_object=a_probe_object)
# deploying template
a_morphogen2_stack_object.create_assume_role_config('<role_to_assume_to_target_account>','<account_number_you_want_to_deploy_to>','<region_to_deploy_to>')
# if the stack doesn't exist already create it, otherwise do an update.
a_morphogen2_stack_object.universal_deploy_update_from_template(a_garden_template_object_for_serverless_autoscaling_microservice,'<name_you_want_your_stack_to_have>',region_name='<region_to_deploy_to>')
And because you set WantsEFS to True you’ll get an EFS made for you and mounted to all your containers at /mnt/efs. Because you set WantsS3Bucket to True you’ll get an S3 bucket all your containers will have access to. And, because you set WantsRD to True you’ll also get an auto scaling Aurora RDS cluster with rotating credentials in Secrets Manager made accessible to your containers as well. I’ve also encoded a whole bunch of environment variables for you to help you find infrastructure and generalize your code across your different microservices. And even though you didn’t specify anything for it when your cluster hits an average CPU utilization of 50% it’ll autoscale for you to meet demand. There’s a whole host of other parameters you can set to customize the behavior of your microservice but for the sake of brevity I’m not going to include them all. Also, while it’s not in the code example above it’s a single call to our “Utilities” library in Morphogen2 to build a container from a source directory and deploy it to ECR and another single call to the same library to trigger a new deployment from ECR to ECS. Many deploy scripts automatically push out new containers to ECR ahead of updating their microservice stacks and it’s a good way to keep all your container code up to date and deployed without really having to think about any of the infrastructure that accomplishes that.
Also, this script is idempotent and if I ran it multiple times all it would do is scan for any changes and make updates as necessary, but if there were no changes to be made, then none of the stacks created the first time would be altered. The universal_deploy_update_from_template function I’m calling scans to see whether or not a stack of that name in the target account exists already and if it doesn’t it will make it but if it does it will check to see if there are any updates to be made and if there aren’t nothing will happen. Behavior like that makes people a lot more comfortable having deploy scripts set to run automatically when new code is checked in to git.
You might have also noticed that I didn’t have to specify VPCs or subnets in the above example even though I’m for sure going to need to know where those things are in the account to make the infrastructure I described. Well, because I provided a_probe_object it auto-discovered the optimal networking infrastructure I should be using for me and set parameters within my stack appropriately. Probe pairs well with a number of different templates to auto-discover the optimal configuration for certain things for users without them needing to bother to figure out the best way to network a database or choose subnets to deploy containers into or a whole host of other tasks that distract them from writing code.
The library can also ingest YAML templates called MIST (Morphogen2 Infrastructure Simple Templates) and you can describe many AWS accounts worth of infrastructure in a single directory of YAML files.
Here’s an example of a MIST file:
account: <account_to_deploy_to>
ecrstack:
resource_type: stack
template: ecr
parameters:
EcrRepos: ['containerrepo']
deploy_code_to_ecr:
resource_type: utilities_call
call: build_and_push_image_to_ecr
parameters:
path_to_docker_folder: '/path/to/container/code'
ecr_repo_to_push_to: 'containerrepo'
microservicestack:
resource_type: stack
template: serverless_autoscaling_microservice
parameters:
LogGroupName: 'acoolestservice'
Images: ['<account_to_deploy_to>.dkr.ecr.us-east-2.amazonaws.com/containerrepo:latest']
ContainerPorts: [80]
Certificate: '<certificate ARN>'
WantsRDSCluster: 'False'
kinesisstack:
resource_type: stack
template: kinesis
parameters:
stream_parameters: [{"Name": "myStream", "ShardCount": 1},{"Name": "myOtherStream", "ShardCount": 10}]
KinesisStreamARN:
resource_type: probe_call
call: fetch_outputs_from_cloudformation_stack
parameters:
stack_name: 'kinesisstack'
value_to_return: 'KinesisStream1'
type_to_cast_return_value_as: 'str'
TriggerNewDeployment:
resource_type: utilities_call
call: trigger_new_deployment
parameters:
cloudformation_name: "microservicestack"
dynamostack:
resource_type: stack
template: dynamo_db
parameters:
table_parameters: [{"TablePrimaryKey": "BestIndexEver"},{"TablePrimaryKey": "BestIndexEver",'WantsKinesisStreamSpecification':'True',
'KinesisStreamARN': "#!#KinesisStreamARN#!#",'WantsTTLSpecification':"True","TTLKey":"MyTTLKey"}]
So what the above MIST file would do when run would make an ECR repo, build and push my container to said ECR repo, build an autoscaling microservice using that container in the ECR repo, build 2 Kinesis streams, trigger a deployment from ECR to my ECS stack of whatever the latest container code is in my ECR repo, and then build a DynamoDB with a kinesis stream specification that uses one of the streams I built earlier in the template. The template is idempotent and if I ran it again it would scan for any changes and make updates as necessary, but if there were no changes to be made, then none of the stacks it created the first time would be altered. To run the template I can run the following code chunk that relies on our Architect class:
from morphogen2 import Architect
if __name__ == "__main__":
Architect.architect().set_state()
That code, without any parameters set, will scan the directory it’s being run in for a folder named “config” and then will iterate through any MIST files contained therein. It will also auto discover optimal parameters for things without needing to have a probe object supplied and it will handle figuring out the best way to assume a role and deploy into a target account for you.
It’s a really easy and readable way to manipulate and maintain a large amount of infrastructure across a large number of accounts and the syntax has so far been pretty well received. The hope is that over time people will start to drift towards common configurations for git repos that leverage MIST and Morphogen2 and this will result in a shared knowledge base that will accelerate overall development at Ginkgo.
Morphogen2 has been creating a positive feedback loop. As we solve problems in AWS we gain more experience which allows us to improve the library which in turn allows us to solve problems faster and gain more experience that in turn allows us to improve the library faster. Most importantly to me it’s aligned the goals of the Software and DevOps teams. We both have a vested interest in improving and contributing to Morphogen2. Primarily the library is used by people in the Digital Tech Team but there’s ongoing efforts to try to target future work at teams in the foundry and beyond. My hope is that in the not too distant future there’s a version of Morphogen2 with an easy to use UI that allows scientists and other people who aren’t necessarily Software or DevOps engineers to rapidly build their own apps and digital infrastructure to accelerate science happening at Ginkgo.
(Feature photo by Jack Dylag on Unsplash)
